November 22, 2024

An Escalent Case Study Diving Into the Three Critical Dimensions for AI Success
In today’s AI-driven world, relentless focus on better, faster decisions is fueled by machine intelligence making meaning of vast data, generated and collected at high velocity. Yet the data are often a tangled mess—multi-structured and multi-varied, siloed, inconsistent and indigestible. Such data are difficult to process, understand or use. Concerns about data veracity and bad data causing biases and hallucinations in AI outcomes remain a key discussion topic and often question the business case and value around such data.
What then are ‘good data?’ Business users point to three critical dimensions: Context (nuance and use cases), Accuracy (completeness and quality) and Efficiency (speed and processing time). However, to get good data, decision makers often struggle to balance manual efforts vs. automated data processing. The need to add a layer of human intelligence and oversight over machine efficiencies remains a key component of any model development, yet carving out human bandwidth is often a challenge. Between reallocating internal resources and de-prioritizing crucial commitments, it is important to ensure in-house AI experts remain focused and true to their roles.
To demonstrate how clients can overcome data challenges in AI, here’s a real-life example of how subject matter experts (SMEs) with a solid, disruptive AI offering were being slowed down by data issues—and how Escalent helped them solve the problem.
Bespoke Solutions for Data Challenges: Building Robust AI Models
Note: This case study is built on a live Escalent project which has been scrubbed and blinded to maintain client confidentiality.
Issue
Our client empowers players in the chemicals and materials industry with industry-disrupting AI research offering that cuts down R&D time and investment through faster modeling and analysis of laboratory data and scholarly journals. The ability to (quickly) clean and synthesize accurate and digestible data assets from over 1,500 documented experiments and several hundred research papers and patent claims from the past decade was fundamental to this work.
Challenges included scattered and indigestible data housed in different silos and emerging from different information sources, poor quality historical records, and inconsistent data management, making it unsuitable for the AI model. Senior data scientists and AI visionaries were tasked with this cleaning effort, taking valuable time away from mission-critical efforts and strategic priorities. Additionally, the AI data automation tools they were using were often not comprehensive and left too many details and gaps in contextual nuances open for further human review.
Process
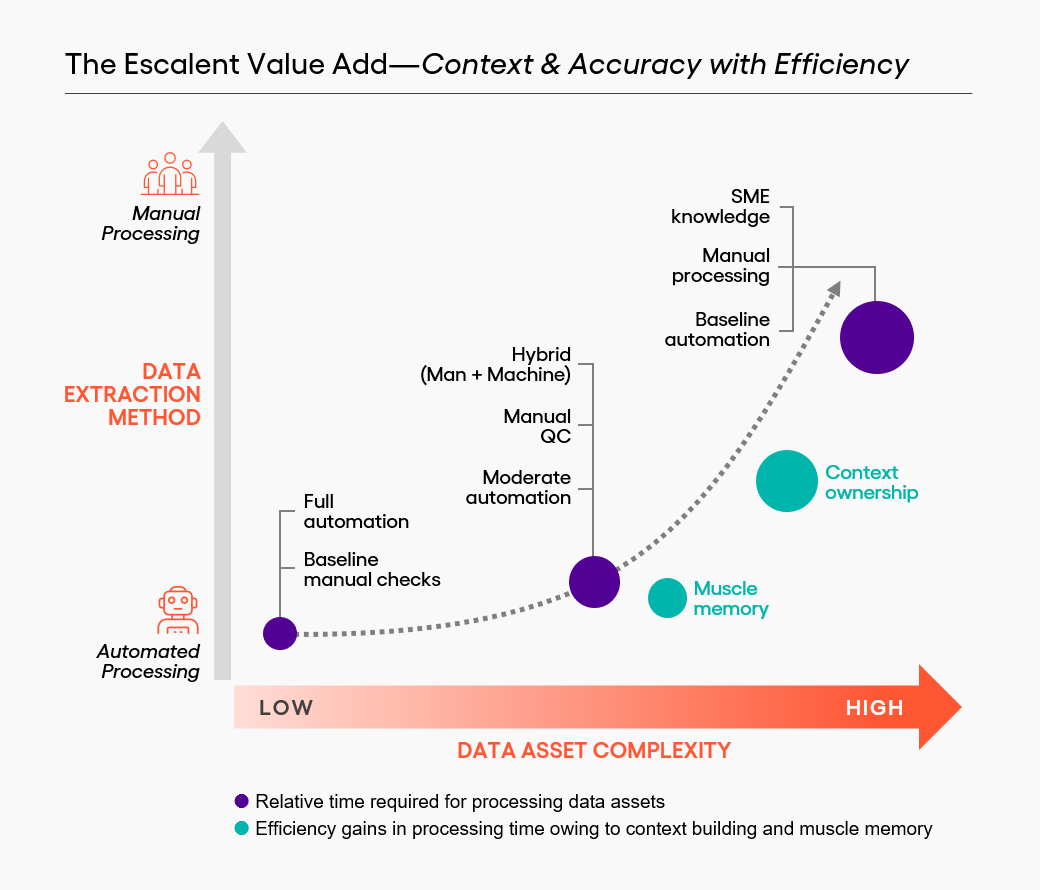
We developed a bespoke solution to process data assets and synthesize patents/journals and created a robust AI training data repository that could be harnessed into an AI learning model. Then we created a system to build context of the data assets and instituted a data processing pipeline with context and scale synergies as we progressed. We achieved this in three phases:
Phase 1—Building Data Context for AI: We collaborated with our client’s stakeholders to develop a well-rounded understanding of the end objective and the nuances that had to be borne in mind while processing the data assets. Context building was also key to identifying relevant data and weeding out incomplete or redundant data (or data that were too specific/use-case dependent to be included in the repository). To better grasp the data context, we ensured that our team had someone with a chemical engineering background, bringing a subject matter lens to bear.
Phase 2—Ensuring Data Accuracy for Good AI Outcomes: Processing data with quality and completeness was critical. To optimize efforts, while keeping the bar of accuracy high, we supplemented manual efforts with image processor and extraction tools to convert data into a structured and digestible format. We took great care to layer tool capabilities with client opinion on tracing relevant data points and variables from a noisy plot, dealing with unique illustrations and scenarios, and creating a best practice for sanity checks, data accuracy and plugging gaps.
Phase 3—Establishing Efficient Data Processing for AI-powered applications: Then the job was to process data at speed and within a time limit to align with the client’s milestones. We segregated data assets into three buckets and used a combination of ongoing client interactions, support of automated tools and muscle memory of human analysts to process:
- Simpler/Low-complexity data assets that could be entirely processed in an automated manner with speed. Incremental analyst bandwidth was needed for quality and accuracy hygiene checks.
- Mid complexity data required a higher proportion of manual efforts for preparing the data ahead of automated processing or for quality and completeness checks post processing.
- High complexity data with indigestibility, missing information, or unique cases, where automated processing achieved a baseline, while manual efforts in terms of context and quality alignment led to optimal results.
Over time, data assets that were once of mid complexity became low complexity. Similarly, highly complex data assets required less client intervention, freeing up nearly 25-30% client bandwidth (spent on data asset processing and synthesizing) initially and increasing to 60-70% as the engagement matured.
Result
Escalent’s multi-dimensional AI-ready data approach optimized efforts on the client side, feeding data to its repositories or running simulation cycles for the AI learning systems. In addition, the credibility and insight-richness of the outcome generated by AI based on data processed by Escalent increased. In the end, the client enjoyed a 2x gain in processing speed, which was complemented by a 3x impact on feeding contextualized and accurate data to the client’s AI.
Balancing human expertise and machine efficiency (human-AI collaboration) to optimize the right blend for your specific situation is a critical question facing AI technologists and executives. At least until automated data processing tools become more sophisticated and offer a reliable path to solving these challenges, especially when it comes to untested waters in emerging verticalized use cases, the value of human reasoning will stay true.
The challenges of conflicting priorities and bandwidth caps are very real. As this case study illustrates, it is imperative for business leaders to strategically assess build vs. buy decisions and keep an eye on long-term AI capability development. There is tremendous upside in nurturing a partner ecosystem that enables agility, flexibility and efficiency to gain a competitive edge.
Special thanks to Abhinav Dua and Gaurav Agrawal for being mentors and to Karamjot Singh and Nikita Jaiswal for providing the research and insights highlighted in this blog post.
Want to learn more? Let’s connect.

Parikshit Sinha
Director, Research & Insights
A seasoned insights and strategy professional, Parikshit is a delivery leader for Technology, Media and Telecommunications projects at Escalent. He specializes in leveraging the power of secondary and human experience research (from consumers to decision makers) to deliver actionable insights and inform clients’ POVs. Prior to joining Escalent, Parikshit worked with firms such as Deloitte and KPMG where he led several insights-driven programs and published thought leadership in international platforms such as The Wall Street Journal. He holds an MBA with a dual specialization in marketing and finance. Outside of work, Parikshit is an illustrator, blogger, fiction writer and podcast host. He lives with his parents in a quaint river valley town called Maithon Dam.